



前提
- 需要明确什么是索引
- MySQL索引使用规则
这两点基本上八股文都会背,就不赘叙了.
问题
为什么这么说呢,相信都有看到,如果在使用LIKE 查询的时候 将 % 放在前面那么%filed filed字段索引将会失效,违背了索引有序排列的规则,就会造成索引失效,从而进行全表扫描
这时候的设计方式就是将%放在右侧,即filed %格式,此时索引就能正常使用
那会不会有一种情况,即使使用了filed %格式,mysql 也没有使用索引去进行查询 ?
看一种情况:
这是一个学员离职入职历史记录表 company_staff_history , 注释都有标明
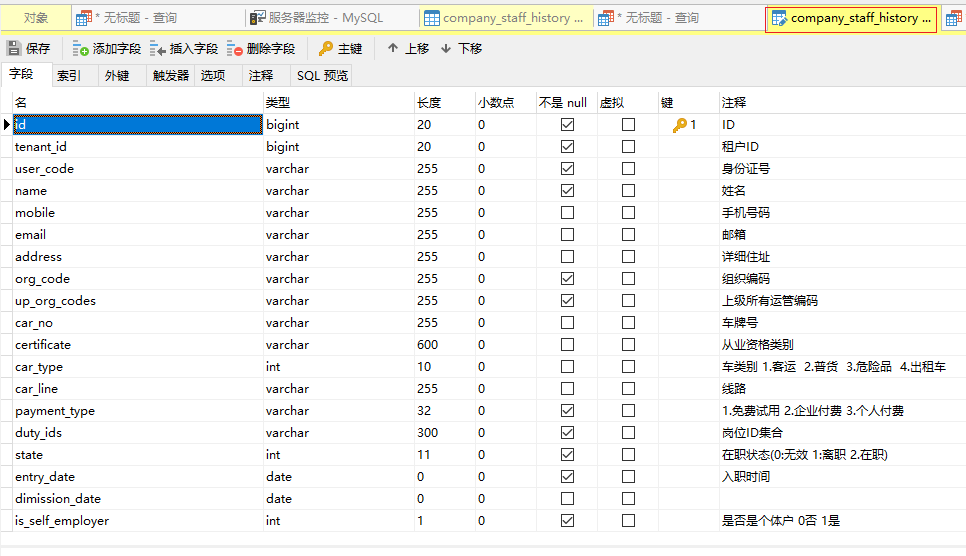
其中, up_org_codes是根据各级行政区划编码当前公司的自定义编码以逗号隔开的字符串
也是本次测试使用的字段,看一下格式:

再确认下记录总数:
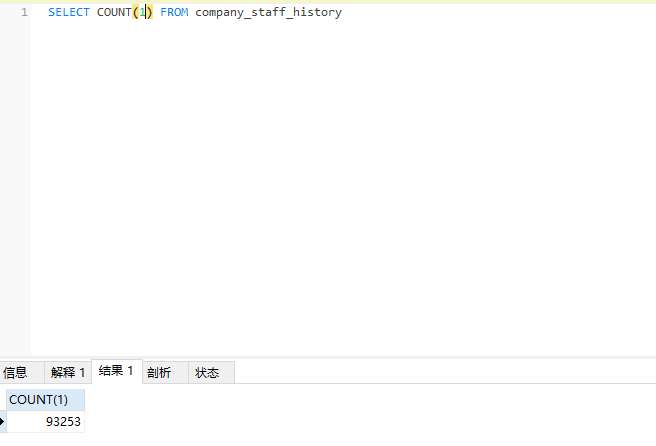
总共 93253 条数据
再确认下分布规律:
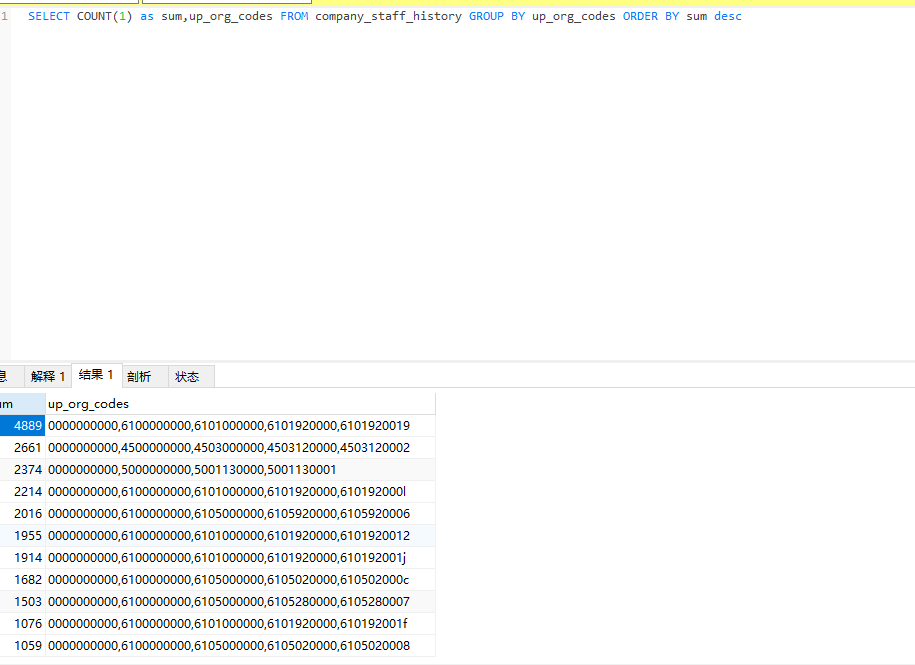
最多的为0000000000,6100000000,6101000000,6101920000,6101920019 占4889条
想要的一个结果,我们通过
up_org_codes字段 查询 0000000000,6100000000,6101000000下的数据
**语句: **
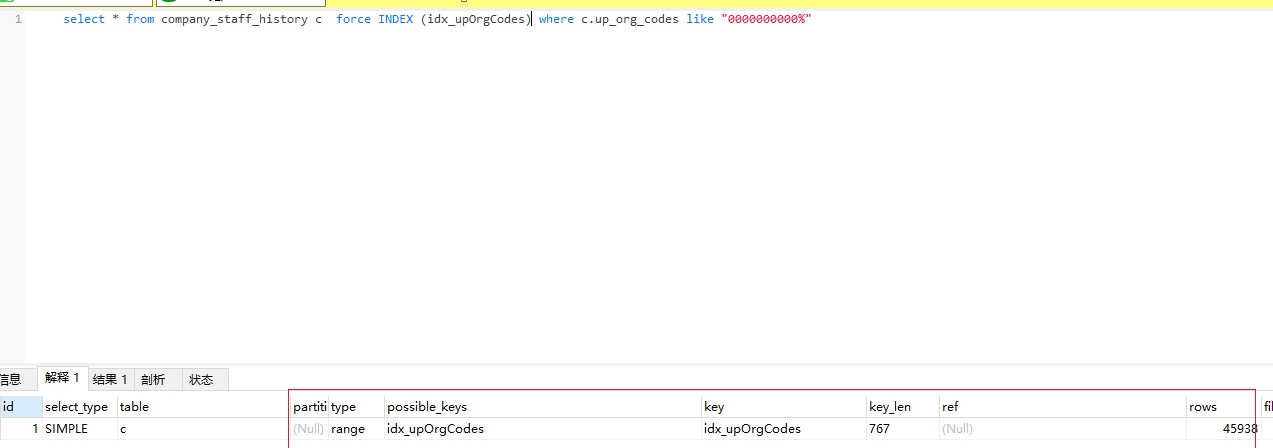
select * from company_staff_history c where c.up_org_codes like "0000000000,6100000000,6101000000%"
按照之前我们学到的结论,这个字段是会走索引的,没问题吧,看一下结果:
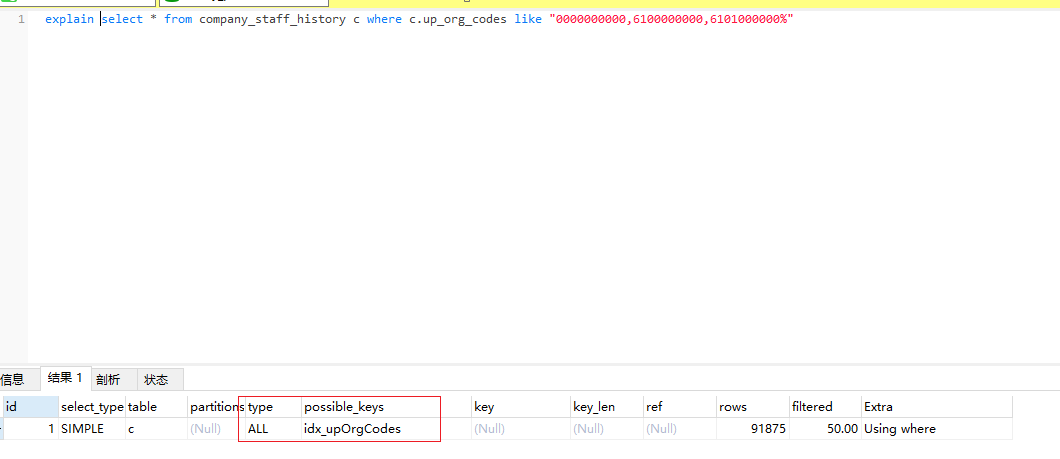
它竟然没有走索引,或者说mysql没有使用索引去查询结果,结果一共 91875 条. 啧,跟我们想象的不一样
再试下 查询 0000000000,6100000000,6101000000,6101130000 下的学员信息
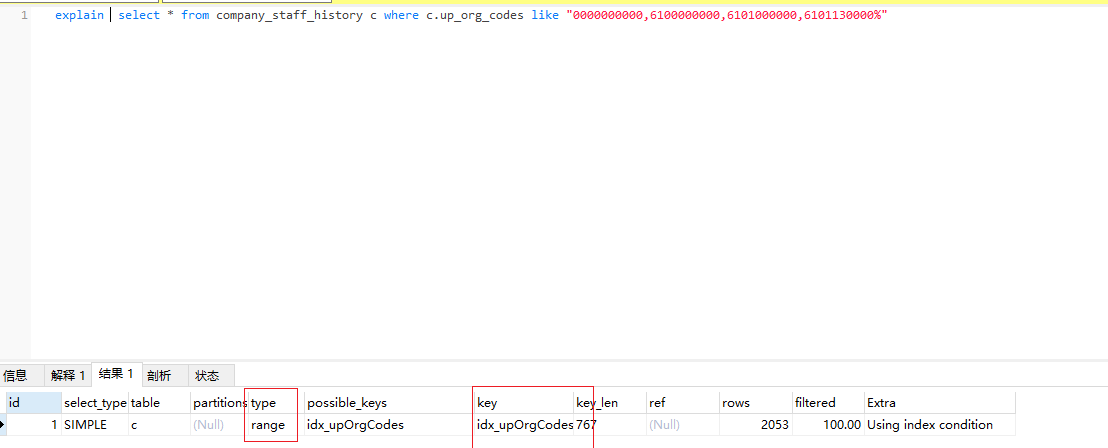
此时竟然又能使用索引,或者说mysql选择去使用索引了, 结果一共2053条, 这可有点不得所以然了
恩,别急且听我慢慢道来, 不知道细心的同学有没有注意到,我在测试中十分注意数字,注意此处mysql执行计划rows只能起到参考意义,来列一下:
- company_staff_history 总条数 93253条
- 0000000000,6100000000,6101000000右模糊查询 总条数 91875条
- 0000000000,6100000000,6101000000,6101130000右模糊查询 总条数 2053条
第二次匹配mysql 给出的计划总条数就差了不到1300条左右,而第三次匹配差了9w之多,而在这个测试表中全都是以
0000000000开头,而6100000000,占了大多数有63564条,这给了mysql一种错觉,以0000000000,6100000000,6101000000,6101130000开头的,则
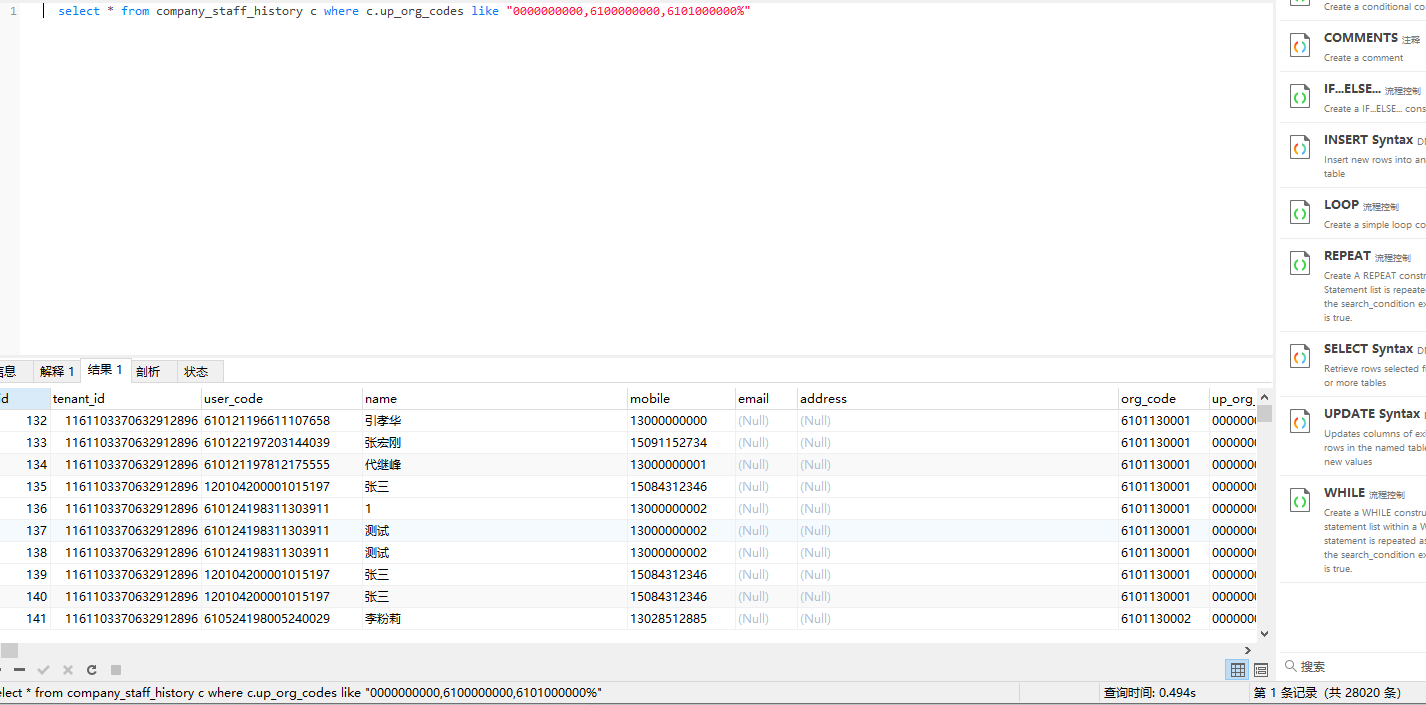
实际上只占了28020条
看下查询效率对比:
未使用索引: 0.443s
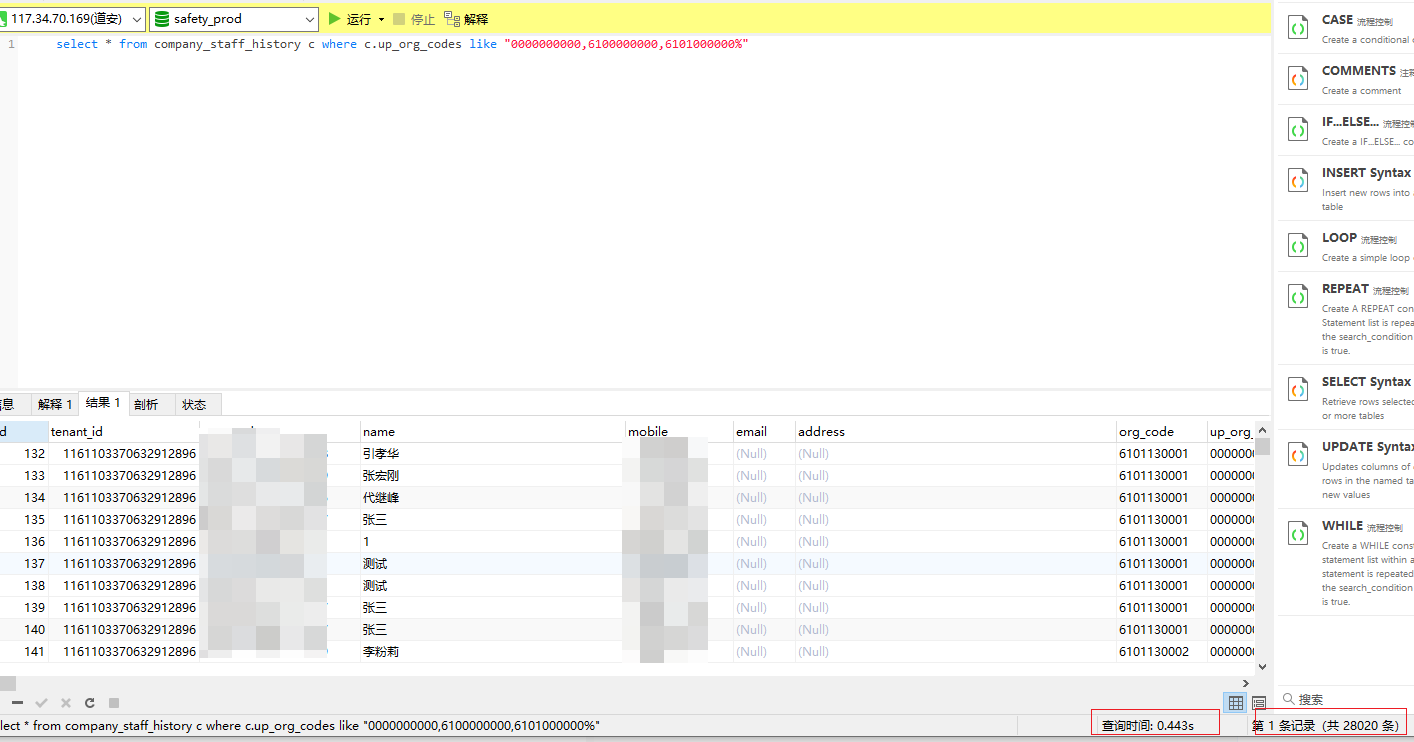
使用索引 0.358s
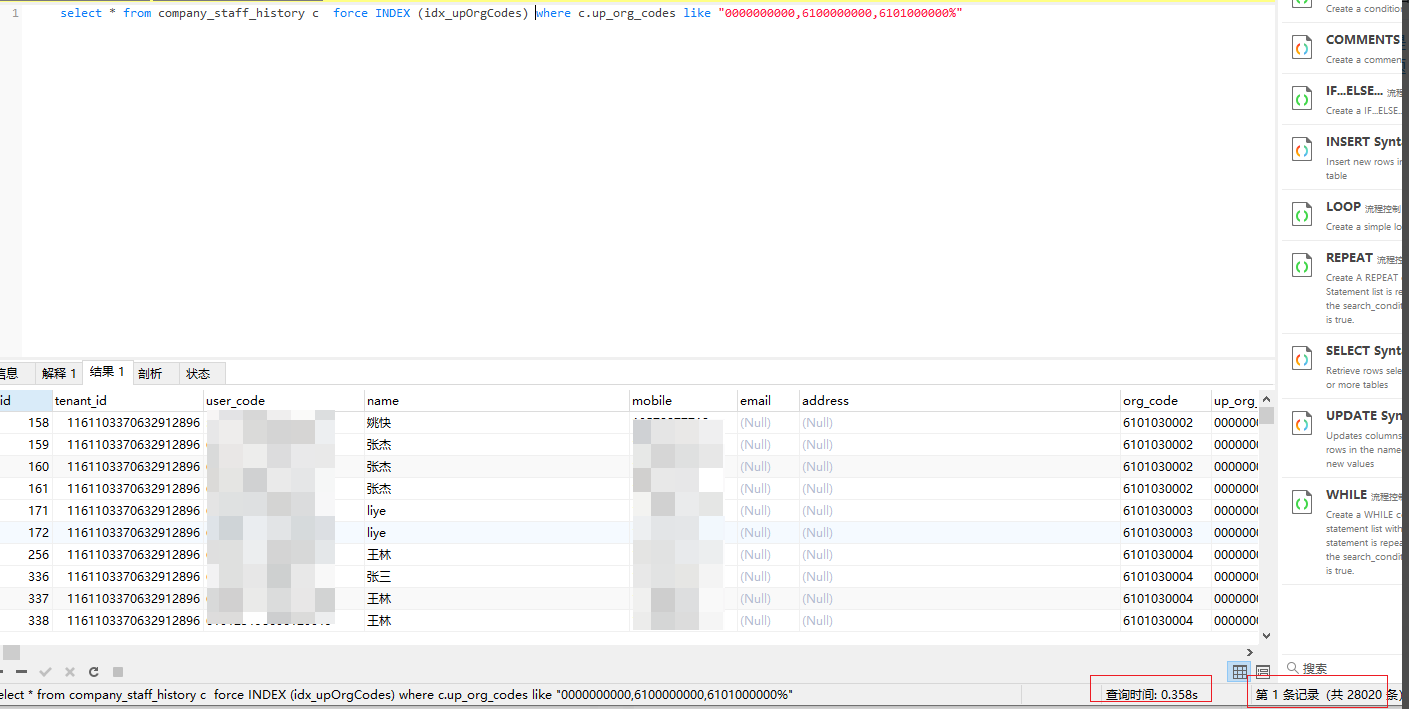
再往前进一步
查询0000000000,6100000000匹配结果
未使用索引: 0.746s左右
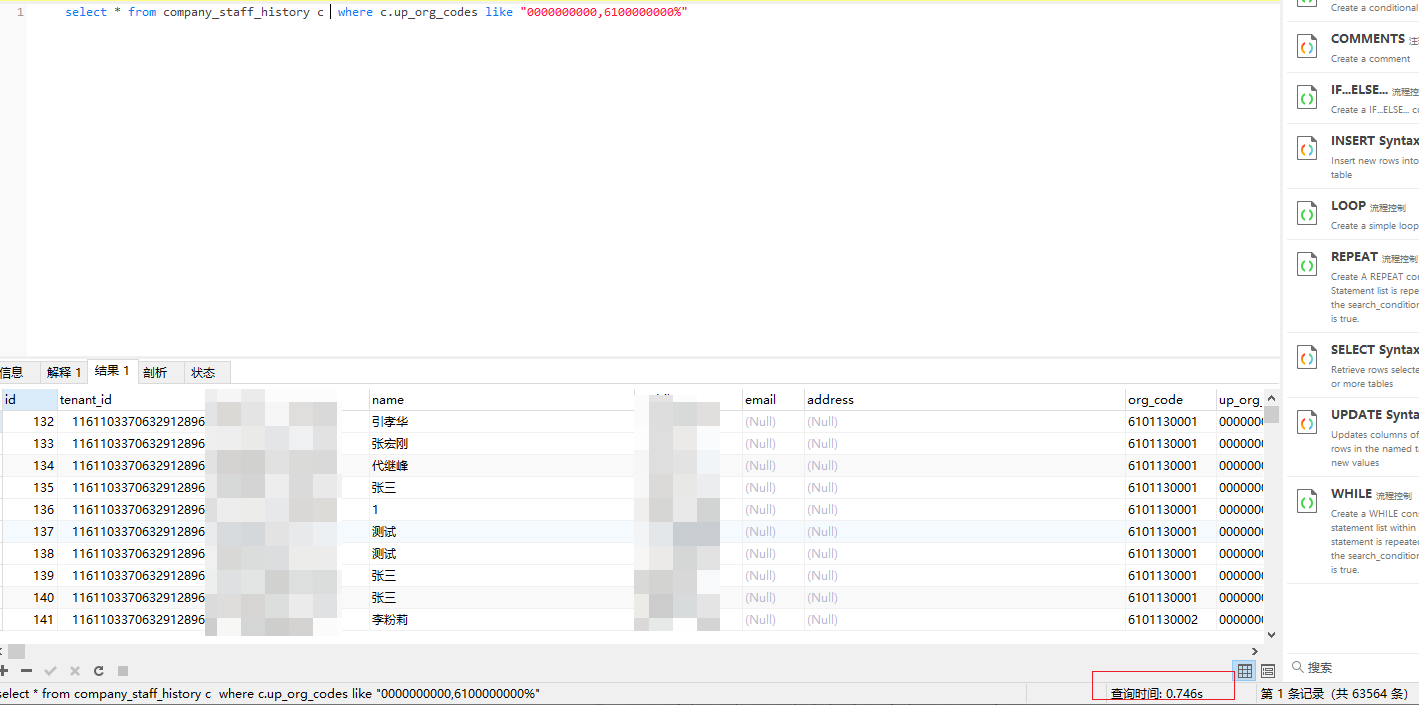
使用索引: 0.733s
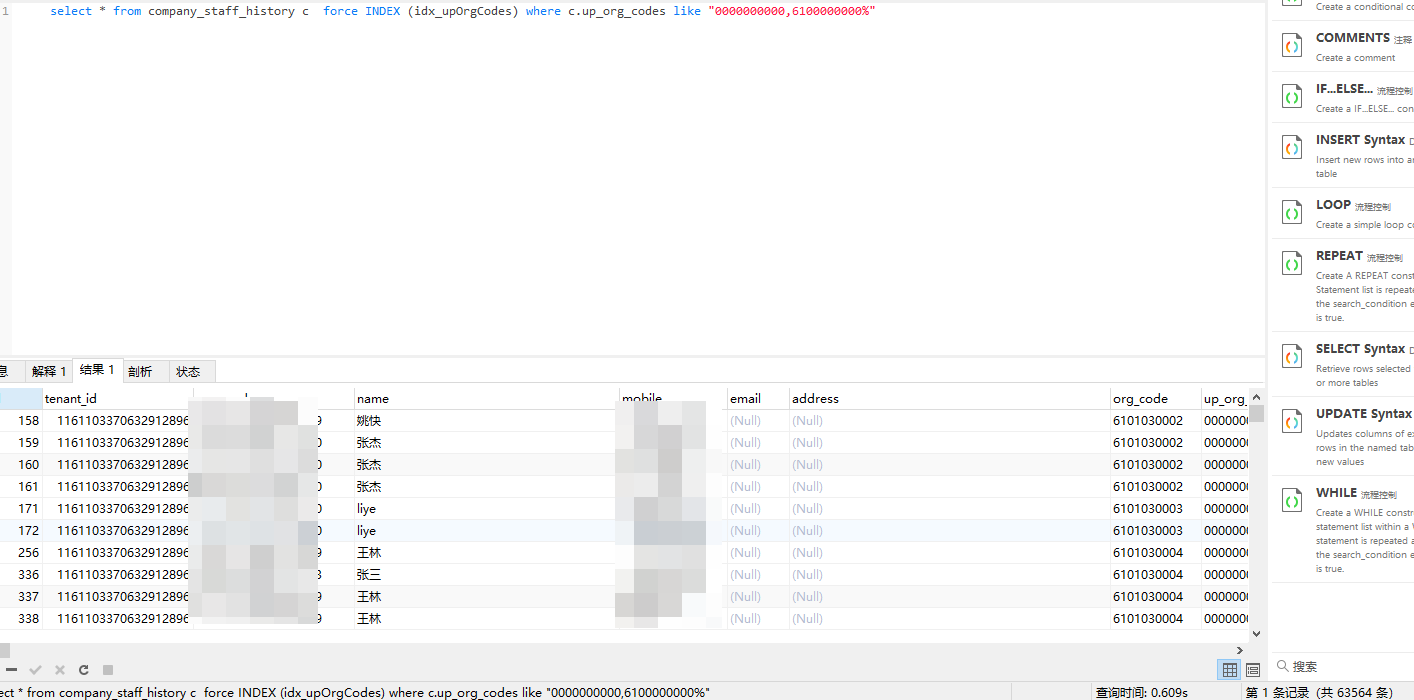
越往前推演,就越接近全表扫描了,直至开头
使用索引:
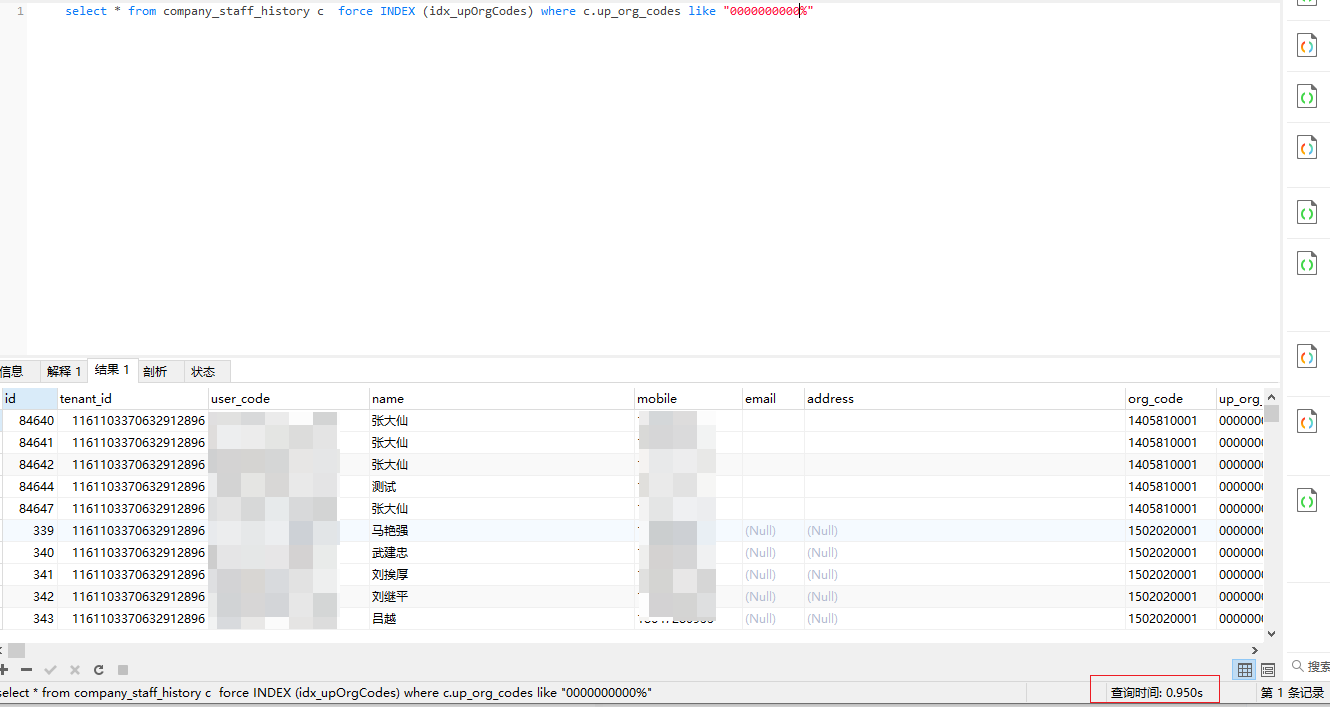
当然这里涉及到其他mysql内部的逻辑,后续再研究
所以…
评论区