



目的
- 熟悉 mongoDB常用的聚合操作
- 会写mongoDB查询语句
- 会将mongoDB查询语句映射到
MongoTemplate上使用(可选)- 最终掌握mongoDB查询的灵活变化
首先确认为什么要用聚合操作?
聚合操作是MongoDB的高级查询语言, 基本的CRUD不满足我们的业务要求, 此时就需要复杂查询来适应并完成, 它主要是按照特定阶段在管道里来对数据做各种处理, 按阶段返回计算结果. 最终得到我们想要的结果.
官话: 聚合管道是一个基于数据处理管道概念建模的数据聚合框架。文档进入多阶段管道,该管道将文档转换成汇总结果
聚合操作的实现
共支持两种计算,一般是使用Pipeline流水线操作 :
Pipeline : db.collectionName.aggregate()
MapReduce : db.collectionName.mapReduce()
aggregate查询
**点击对应的命令运算符会跳到对应的使用页面: **
为了方便使用这里引用下表格 :
阶段表格
| 阶段 | 描述 |
|---|---|
$addFields |
将新字段添加到文档。与相似 $project,$addFields重塑流中的每个文档;具体而言,通过向输出文档添加新字段,该文档既包含输入文档中的现有字段,又包含新添加的字段。$set是的别名$addFields。 |
$bucket |
根据指定的表达式和存储区边界将传入文档分类为多个组,称为存储区。 |
$bucketAuto |
根据指定的表达式将传入文档分类为特定数量的组,称为存储桶。自动确定存储区边界,以尝试将文档平均分配到指定数量的存储区中。 |
$collStats |
返回有关集合或视图的统计信息。 |
$count |
返回聚合管道此阶段的文档数计数。 |
$facet |
在同一阶段的同一组输入文档上处理多个聚合管道。支持在一个阶段中创建能够表征多维或多面数据的多面聚合。 |
$geoNear |
根据与地理空间点的接近程度返回有序的文档流。包含 $match,$sort和$limit用于地理空间数据的功能。输出文档包括附加距离字段,并且可以包括位置标识符字段。 |
$graphLookup |
对集合执行递归搜索。向每个输出文档添加一个新的数组字段,其中包含对该文档的递归搜索的遍历结果。 |
$group |
按指定的标识符表达式对输入文档进行分组,并将累加器表达式(如果指定)应用于每个组。消耗所有输入文档,并在每个不同的组中输出一个文档。输出文档仅包含标识符字段,如果指定,还包含累积字段。 |
$indexStats |
返回有关集合每个索引使用情况的统计信息。 |
$limit |
将未修改的前n个文档传递到管道,其中n是指定的限制。对于每个输入文档,输出一个文档(对于前n个文档)或零文档(在前n个文档之后)。 |
$listSessions |
列出所有活动时间已经足够长以传播到system.sessions集合的会话。 |
$lookup |
对同一数据库中的另一个集合执行左外部 联接,以过滤“联接”集合中的文档以进行处理。 |
$match |
筛选文档流,以仅允许匹配的文档未经修改地传递到下一个管道阶段。 $match使用标准的MongoDB查询。对于每个输入文档,输出一个文档(匹配)或零文档(不匹配)。 |
$merge |
将聚合管道的结果文档写入集合。该阶段可以将结果合并(插入新文档,合并文档,替换文档,保留现有文档,使操作失败,使用自定义更新管道处理文档)将结果合并到输出集合中。要使用该$merge阶段,它必须是管道中的最后一个阶段。4.2版中的新功能。 |
$out |
将聚合管道的结果文档写入集合。要使用该$out阶段,它必须是管道中的最后一个阶段。 |
$planCacheStats |
返回集合的计划缓存信息。 |
$project |
重塑流中的每个文档,例如通过添加新字段或删除现有字段。对于每个输入文档,输出一个文档。另请参阅$unset删除现有字段。 |
$redact |
通过基于文档本身中存储的信息限制每个文档的内容,来重塑流中的每个文档。包含$project和的功能 $match。可用于实施字段级修订。对于每个输入文档,输出一个或零个文档。 |
$replaceRoot |
用指定的嵌入式文档替换文档。该操作将替换输入文档中的所有现有字段,包括该_id字段。指定嵌入在输入文档中的文档以将嵌入的文档提升到顶层。$replaceWith是$replaceRoot舞台的别名 。 |
$replaceWith |
用指定的嵌入式文档替换文档。该操作将替换输入文档中的所有现有字段,包括该_id字段。指定嵌入在输入文档中的文档以将嵌入的文档提升到顶层。$replaceWith是$replaceRoot舞台的别名 。 |
$sample |
从其输入中随机选择指定数量的文档。 |
$set |
将新字段添加到文档。与相似 $project,$set重塑流中的每个文档;具体而言,通过向输出文档添加新字段,该文档既包含输入文档中的现有字段,又包含新添加的字段。$set是$addFields舞台的别名。 |
$skip |
跳过前n个文档,其中n是指定的跳过编号,并将其余未修改的文档传递到管道。对于每个输入文档,输出零个文档(对于前n个文档)或一个文档(如果在前n个文档之后)。 |
$sort |
通过指定的排序键对文档流重新排序。只有顺序改变;这些文档保持不变。对于每个输入文档,输出一个文档。 |
$sortByCount |
根据指定表达式的值对传入文档进行分组,然后计算每个不同组中的文档数。 |
$unset |
从文档中删除/排除字段。$unset是$project删除字段的阶段的别名。 |
$unwind |
从输入文档中解构一个数组字段,以输出每个元素的文档。每个输出文档用元素值替换数组。对于每个输入文档,输出n个文档,其中n是数组元素的数量,对于空数组可以为零。 |
资料目标
参阅资料后我们需要明确几个概念:
- 阶段(stages)
- 表达式
- 表达式对象
- 字段路径
- $literal命令
- 运算符表达式
- 聚合变量
阶段
在流水线的概念中,就分有阶段的概念,在mongoDB中也一样,每个阶段相当于完成了一个当前阶段应该做的事,并将文档按照流水线从上到下的顺序的处理,
快速过一个aggregate操作:
这个操作完成了根据时间进行分组并统计values子文档字段的条数的和:
db.getCollection(<collectionName>).aggregate( -- collectionName对应集合的名称,
[ { -- 每个阶段需要用大括号包起来,首位对应
"$project": { -- project 阶段 表示当前阶段处理下来剩余的字段,并能对字段做特殊处理
"data_time":1, -- 表示使用该字段
"value_count": {"$size":"$values"}-- 表示将values字段的大小统计起来,赋值给新建的字段value_count
}
}, -- 当前阶段结束, 阶段之间逗号隔开, 这时的字段列为 _id,data_time,value_count
{"$group":{ -- 第二个阶段开始,聚合操作即分组的概念
"_id":"$data_time", -- 标识以那些字段来做分组的依据,这里使用data_time
"data_time":{"$first":"$data_time"}, -- $first表示需要显式的字段赋值给data_time
"data_count": {"$sum":"$value_count"} -- $sum表示将字段value_count的值基于分组汇总起来,并赋值给新字段data_count
}},
{"$project":{"_id":0}} -- 为0时表示不需要返回字段ID
]
)
结果如下:
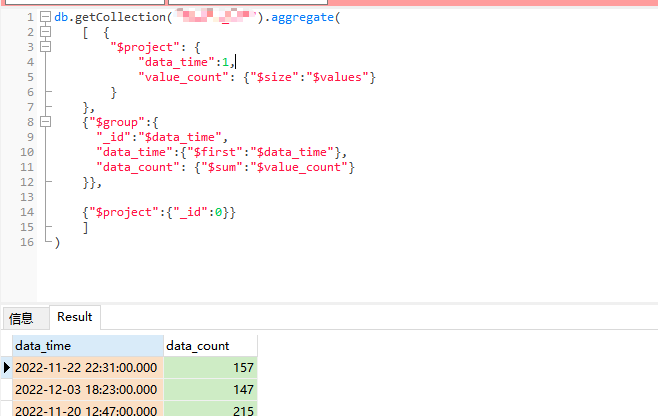
可以得到以下几点信息:
-
db.getCollection(xx).aggregate([])标准查询操作,[]中是我们的查询条件阶段编写的地方 -
阶段之间使用
,隔开, 阶段内使用{}确定域, 开始的$project/$group必须用$开头且只能在阶段中选用, 表示该阶段要做什么操作,常用的还有$match/$count/$sort/$limit/$skip等等 -
每个阶段下都有自己特殊的操作运算, 如
$project下有$size,$group下有$first/$sum等等 -
每个阶段结束都会有自己的操作结果,并且影响到下一个阶段, 如上述查询中, 第一个
$project去掉"data_time":1,如下:db.getCollection(<collectionName>).aggregate( [ { "$project": { "value_count": {"$size":"$values"} } }, {"$group":{ "_id":"$data_time", -- 这里的结果运算就会出问题, 前面的project已经定义了阶段完成后的字段,只有一个value_count, 并不存在$data_time字段 "data_time":{"$first":"$data_time"}, "data_count": {"$sum":"$value_count"} }}, {"$project":{"_id":0}} ] )一般情况下找不到引用的字段会报错, 但是在
$group操作这里并不会报错, 因为group操作支持null操作, 找不到当前$data_time就用null代替,所以最终的结果在原本正确查询有结果的情况下,现在查询有且只会有一行数据,具体参与$group运算符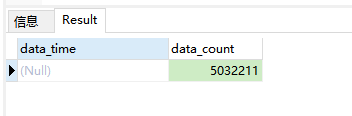
- 阶段内的写法必须以
json的格式书写, mongo提供的阶段操作,都需要添加$来进行操作,否则会不识别 - 想引用字段就要使用
$字段名[字段路径], 想定义自定义字段名直接使用字段名即可
- 阶段内的写法必须以
表达式
包括上述5个
-
表达式对象
{ <field1>: <expression1>, ... }即上述的$group等格式 -
字段路径 想要引用字段,前置必须添加
$,$field的格式, 如果包含子文档则为$sonDoc.field -
literal
命令 返回一个不解析的值 即如果在上述group中使用命令来替换$data_time`:db.getCollection(<collectionName>).aggregate( [{ "$project": { "data_time": 1, "value_count": { "$size": "$values" } } }, { "$group": { "_id": { "$literal": "$data_time" }, "data_time": { "$first": "$data_time" }, "data_count": { "$sum": "$value_count" } } } ] )运行结果如下:
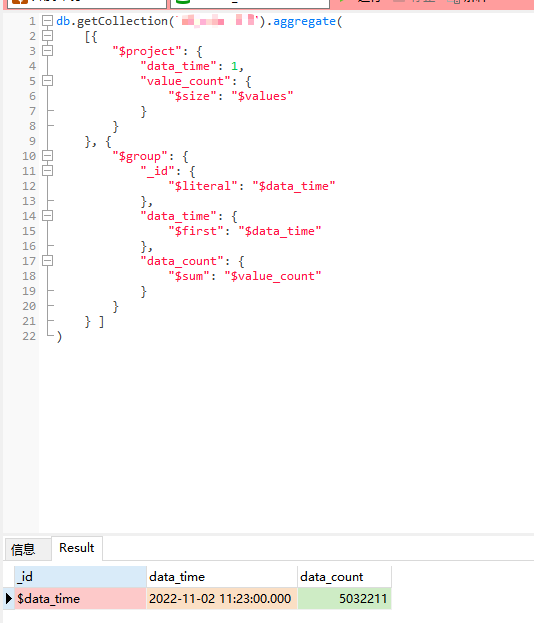
-
运算符表达式
略, 参考各阶段中表达式书写写法
-
聚合变量
这里分为用户变量和系统变量, 同流水线一样, 用户变量和系统变量都是可以跨阶段使用, 但是在顺序执行中没有定义的变量是无法向上使用的,这点需要注意:
-
变量可以保存任何BSON类型的数据。要访问变量的值,请在变量名前加上双美元符号(
$$);即"$$<variable>"。 -
如果变量引用一个对象,则要使用该点访问该对象中的特定字段;即
"$$<variable>.<field>"。 -
用户变量名称可以包含ASCII字符
[_a-zA-Z0-9]和任何非ASCII字符。 -
用户变量名称必须以小写字母
[a-z]或非字母字符开头
具体的系统变量参考:
-
-
开始编写SQL
首先设计一张表
db.createCollection("Test01");
db.getCollection("Test01").insert([ {
name: "张三",
age: 18,
address: "陕西省西安市雁塔区",
hpbby: "football"
} ]);
db.getCollection("Test01").insert([ {
name: "李四",
age: 18,
address: "陕西省西安市雁塔区",
hpbby: "football"
} ]);
db.getCollection("Test01").insert([ {
name: "王五",
age: 18,
address: "陕西省西安市雁塔区",
hobby: "game"
} ]);
db.getCollection("Test01").insert([ {
name: "张三",
age: 14,
address: "陕西省西安市高新区",
hobby: "football"
} ]);
db.getCollection("Test01").insert([ {
name: "李四",
address: "陕西省西安市高新区",
age: 15,
"hobby": "eat"
} ]);
db.getCollection("Test01").insert([ {
name: "王五",
age: 16,
address: "陕西省西安市高新区",
hobby: "read"
} ]);
db.getCollection("Test01").insert([ {
name: "张三一",
age: 18,
address: "陕西省西安市雁塔区",
hobby: "travel"
} ]);
数据很简单,最终如下,共7条数据,字段分为名称/性别以及地址
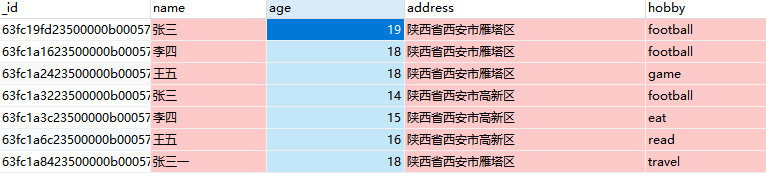
需求1 查询陕西省西安市高新区的各年龄中所占数量,结果显示年龄/姓名集合/爱好集合/地址集合/人员信息集合/总数
分析:
- 查询陕西省西安市高新区 显然是要根据address进行过滤
- 统计各年龄数量, 则是需要使用聚合操作根据年龄进行分组
- 结果显示年龄/姓名集合/爱好集合/地址集合/人员信息/总数,同时将
$sum运算的结果保存到总数中 就是生成各个字段的集合数据与统计数据- 从数据上来看, 高新区的只有三条数据,且年龄都不相同, 所以分组上也只有三组数据,且每组下只有一条数据
OK, 流程整理完成了. 开始实现语句:
- 首先先创建查询
// 首先先创建查询
db.getCollection("Test01").aggregate([]);
-
查询陕西省西安市高新区
// 创建分组 db.Test01.aggregate([ // 第一个阶段,match { "$match":{ // 使用match阶段 "address":{"$eq":"陕西省西安市高新区"} //eq 等于的意思, 后面的为值 } } ])
-
根据年龄分组,并将结果汇总
// 创建分组
db.Test01.aggregate([
// 第一个阶段,match
{
"$match":{
"address":{"$eq":"陕西省西安市高新区"} //eq 等于的意思, 后面的为值
}
},
//第二个阶段分组
{
"$group":{
"_id":"$age", //根据年龄分组
"people": {"$push":"$$ROOT"} // 将分组结果推送到people字段中
}
}
])
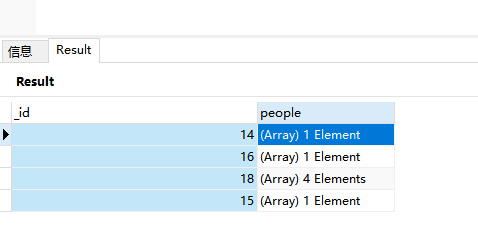
people字段信息如下
- 在年龄分组的基础上,显示统计的总数以及集合
// 创建分组
db.Test01.aggregate([
// 第一个阶段,match
{
"$match":{
"address":{"$eq":"陕西省西安市高新区"} //eq 等于的意思, 后面的为值
}
},
//第二个阶段分组
{
"$group":{
"_id":"$age", //根据年龄分组
"people": {"$push":"$$ROOT"} // 将分组结果推送到people字段中
}
},
//第三个阶段定义字段
{
"$project":{
"_id":0, // 不显示ID
"age":"$_id", //年龄
"nameArray":"$people.name", //聚合同年龄的姓名的集合
"addressArray":"$people.address", // 同年龄的地址集合
"hobbyArray":"$people.hobby", // 同年龄的爱好集合
"peopleArray":"$people",
"sum":{"$size":"$people"} //年龄数 size统计数量
}
}
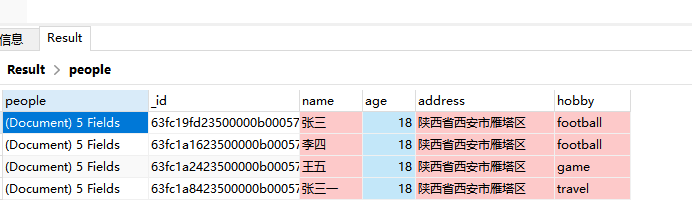
])
结果如下:

nameArray/addressArray/hobbyArray分别是名称地址爱好的统计集合, peopleArray是人员信息的集合, 而sum是当前年龄下的人数,展开后数据如下

- 同时我们看到结果不是按照年龄的升序排序的,我们再对结果集进行排序
// 创建分组
db.Test01.aggregate([
// 第一个阶段,match
{
"$match":{
"address":{"$eq":"陕西省西安市高新区"} //eq 等于的意思, 后面的为值
}
},
//第二个阶段分组
{
"$group":{
"_id":"$age", //根据年龄分组
"people": {"$push":"$$ROOT"} // 将分组结果推送到people字段中
}
},
//第三个阶段定义字段
{
"$project":{
"_id":0, // 不显示ID
"age":"$_id", //年龄
"nameArray":"$people.name", //聚合同年龄的姓名的集合
"addressArray":"$people.address", // 同年龄的地址集合
"hobbyArray":"$people.hobby", // 同年龄的爱好集合
"peopleArray":"$people",
"sum":{"$size":"$people"} //年龄数 size统计数量
}
},
//第四个阶段排序
{
"$sort":{
"age":1
}
}
])
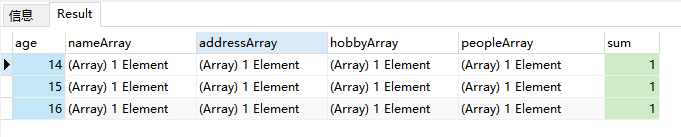
这样这个需求就完成了
需求2 查询各地址下爱好为football的人员信息,结果只展示年龄最大的一个人信息
分析:
- 各地址 意思根据地址分组
- 爱好为football 配置各地址下爱好为football的数据
- 只取年龄最大一条数据,
- 从数据上看分别为高新区和雁塔区,
- 雁塔区爱好为football的有两条,年龄最大的为张三
- 高新区爱好为football的只有一条,所以年龄最大也只有一个刚好叫张三的但是年龄为14岁的人
// 创建分组
db.Test01.aggregate([
//第一阶段, 查询爱好为football的人员
{
"$match":{
"hobby":{"$eq":"football"}
}
},
//第二阶段, 将结果进行降序排序
{
"$sort":
{
"age":-1
}
},
//第二阶段, 将结果根据地址分组,并取第一条记录传递给people
{
"$group":{
"_id":"$address",
"people":{"$first":"$$ROOT"}
}
},
//还原people内容
{
"$replaceRoot":{"newRoot":"$people"}
}
])
最终结果如下:

总结下来,就是根据需要对掌握的阶段与运算符灵活运用,最终实现方式可能也不只一种
MongoDB与MongoTemplate
这部分内容作为一个扩展内容,不一定是使用Java工具包
在Java提供的包中,流式编程其实和上述结果十分相似,掌握了上述阶段和运算符写Template方法也就很简单
对比下两个的编写方式就能Get到点了
分别将上述需求改写下
需求一
public List<?> test01(){
Criteria equals = Criteria.where("address").is("陕西省西安市高新区");
Aggregation aggregation = Aggregation.newAggregation(
//第一个阶段,match
Aggregation.match(equals),
//第二个阶段,分组
Aggregation.group("age").push("$$ROOT").as("people"),
//第三个阶段,定义字段格式
Aggregation.project("_id", "0")
.and("_id").as("age")
.and("people.name").as("nameArray")
.and("people.address").as("addressArray")
.and("people.hobby").as("hobbyArray")
.and("people").as("peopleArray")
.and("people").size().as("sum")
);
// test01 为表名 Object.class 为返回值的类型, 这里未定义实体所以用Object代替
AggregationResults<Object> results =
mongoTemplate.aggregate(aggregation, "test01", Object.class);
//mappedRresults 即为最终的一个结果
List<Object> mappedResults = results.getMappedResults();
}
需求二
public List<?> test01(){
Criteria equals = Criteria.where("hobby").is("football");
Aggregation aggregation = Aggregation.newAggregation(
//第一个阶段,match
Aggregation.match(equals),
//第二个阶段,裴旭
Aggregation.sort(Sort.by(Sort.Order.desc("age"))),
//第三个阶段将每个分组第一条数据放到people当中
Aggregation.group("address").first("$$ROOT").as("people"),
//第四个阶段还原数据
Aggregation.replaceRoot("people")
);
AggregationResults<Object> results =
mongoTemplate.aggregate(aggregation, "test01", Object.class);
List<Object> mappedResults = results.getMappedResults();
}
总结
学习aggregate查询, 最主要的就是掌握各阶段以及日常开发过程中会使用到的各种类型运算符,等熟悉之后,如何查询其实已经心中有数了,剩下的只是看如何转化成mongoSQL语言去查询, 再就是使用响应开发语言提供的工具包转化成代码.
评论区